When Busy Teams Stop Shipping
You’ve seen this before. Every sprint review, the team reports progress. Tasks move across the board. The Gantt chart fills in on schedule. Then somewhere around month eight of a twelve-month program, reality intrudes. The timeline doesn’t slip by days — it slips by quarters. Scope gets cut. The budget gets renegotiated. And the post-mortem settles on a familiar set of explanations: changing requirements, underestimation, technical debt.
These explanations aren’t wrong, exactly. They’re just describing symptoms. The actual mechanism — the structural reason busy teams stop shipping — was identified over thirty years ago. Almost nobody in data product management has heard of it.
The mechanism hiding in plain sight
In 1993, Kenneth Cooper published a paper in the Project Management Journal that should have changed how every technical leader thinks about project delivery. It didn’t — not because the finding was disputed, but because it was inconvenient.
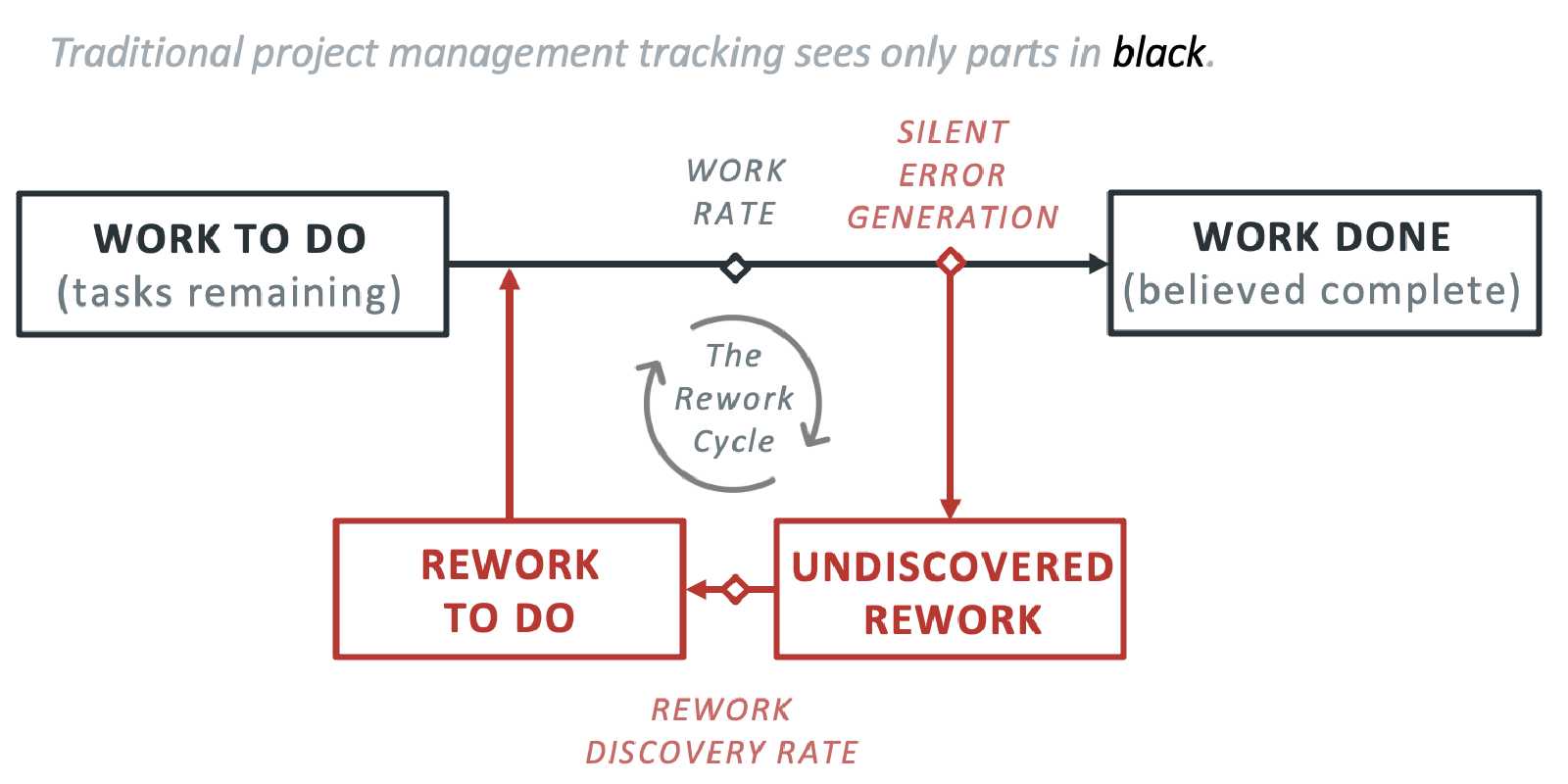
Cooper’s insight was simple. The standard mental model of project management is a pipeline: work flows from “to do” through “in progress” to “done.” For mature, repeatable processes, this model works well enough. But for new product development — where specifications are ambiguous, cross-functional handoffs are frequent, and integration risk is high — the pipeline model is dangerously incomplete.
What’s missing is a feedback loop. When completed work passes through a quality gate — does this component actually fit with the rest of the system? — a portion of it cycles back as rework. Some of that rework is known: the team identifies a bug, logs it, and fixes it. That’s manageable. The dangerous portion is what Cooper called undiscovered rework: tasks that sit in “done” but aren’t actually done. They’ll need to be redone, but nobody knows it yet.
Here’s the problem. Every project plan assumes that undiscovered rework is zero. It never is. The gap between planned rework and actual rework is where schedules go to die. And because undiscovered rework is invisible to the tracking system — it looks like completed work — it creates a steadily widening gap between reported progress and real progress. That gap is why teams can look productive for months and have nothing ready to ship. Every senior technical leader has lived through it at least once.
Cooper’s framework has been validated across defense procurement and construction. It has near-zero penetration in data product management. That’s a problem, because data products are especially vulnerable to it.
Why data products amplify the rework cycle
Data products have three characteristics that make undiscovered rework almost inevitable if you don’t actively design against it.
First, specifications tend to be ambiguous in ways that aren’t obvious. “The model should be accurate” can mean ten different things to ten different stakeholders. “The dashboard should show key metrics” defers every hard design decision to the development team, who will guess — and guess differently from what the stakeholder imagined. These gaps don’t surface during development. They surface during integration and user acceptance, when the cost of correction is highest.
Second, cross-functional handoffs between domain experts and engineers create translation loss. A commodity analyst who understands the market structure and a data scientist who understands optimization solvers may both be individually excellent and still produce a system that doesn’t work — because the mathematical formulation doesn’t capture a business constraint that the analyst assumed was obvious, or because the solver architecture can’t accommodate a workflow the analyst never described.
Third, quality gaps in data products are often invisible until the system is assembled. A pricing model can be mathematically correct but operationally unusable. A user workflow can be technically functional but wrong for the user’s actual decision process. These aren’t bugs in the traditional sense. They’re fit problems — the component works in isolation but fails in context. And they sit in the “done” column, undetected, until someone tries to use the product end-to-end.
The failure mode here isn’t bad engineering. It’s insufficient specification upstream, which creates a reservoir of undiscovered rework that detonates during integration.
What changes when you manage against it
I ran a cross-departmental product development project for a European energy client — a cloud-based optimization tool that had to handle legislative constraints across multiple markets, with a mix of domain consultants and data scientists building the solution jointly. The kind of project that routinely runs late.
We designed the entire process around one principle: minimize undiscovered rework by refusing to write code until the specification had been stress-tested to the point where ambiguity had nowhere left to hide.
That meant producing not one specification document, but six — each targeting a different dimension of the product. The mathematical formulation was written out in full notation so the optimization logic could be validated independently of the software. A clickable wireframe — fifty-seven pages of low-fidelity mockups — defined every user workflow in granular detail, so design gaps became self-evident before a single line of code was written. An Excel-based reference model established expected input-output pairs, giving the development team a concrete validation target. The data schema, permissions logic, and process flow charts each had their own dedicated documents.
Only after all six documents were locked did we build the development timeline. The Gantt chart was the last thing we produced, not the first.
The project delivered on time and within budget. Not because the team was unusually talented — they were good, but so are most teams that end up delivering late. It delivered because the rework reservoir was drained before development began. The specification phase was where the hard problems got solved. Development, by comparison, was straightforward execution.
The uncomfortable implication
The reason most teams don’t do this is not that they disagree with it. It’s that front-loaded specification feels slow. Stakeholders want to see code, not wireframes. Boards want velocity metrics, not “we’re still in design.” There’s institutional pressure to demonstrate progress — and the easiest way to demonstrate progress is to start building.
There’s a saying, usually attributed to Lincoln: “Give me six hours to chop down a tree and I will spend the first four sharpening the axe.” Most data product teams do the opposite. They pick up a dull axe and start swinging immediately, because swinging looks like progress. Four months in, the tree has barely moved, and now they’re sharpening the axe while trying to chop — which is another way of describing rework.
Cooper’s framework predicts exactly this dynamic. The pressure to show progress is what causes teams to skip the work that would actually create progress. The result is a project that looks fast for the first two-thirds and then stalls — because it’s now doing the specification work it should have done at the start, except now it’s doing it through rework at ten times the cost.
Sharpen the axe first. The tree comes down faster.
Is this your portfolio?
Three questions worth asking about any data product program currently in flight:
Can your team quantify how much of their “completed” work has been validated against the specification — not against individual ticket acceptance criteria, but against the integrated system design? If the answer is “we don’t have a specification detailed enough to validate against,” you have an undiscovered rework problem. You just don’t know how large it is yet.
When was the last time your development timeline was rebuilt from a locked specification, rather than estimated at the start and adjusted as surprises emerged? If the timeline came first and the specification is still evolving, you’re planning as though undiscovered rework is zero.
If a new team member joined the project tomorrow, could they understand the full scope of the product — its mathematical logic, user workflows, data structure, and permissions model — from documentation alone, without asking anyone? If not, the knowledge required to build the product lives in people’s heads, which is where undiscovered rework hides.
If any of these questions land uncomfortably, the Rework Cycle is worth understanding properly. It won’t tell you what’s wrong with your specific project — but it will tell you where to look.